Project 1
Housing Data Scraped from Zillow
The first step I took for this exercise is to initially create a database by running code to scrape n=400 houses directly from Zillow’s website. I initially completed this step in class using the first iteration of the zillow_scrape.py code, and this is the database which I used in this project. After successfully scraping the data following our instruction in class, I attempted to create another database from housing data in Miami, FL. However, by this time the ingenious data scientists at Zillow had made an alteration to their website code that rendered my zillow_scrape.py functionally useless.
Given this alteration, I reverted back to my original dataset of Austin, TX. A quick check of the data showed that there were about eight seemingly random errors in transcribing house prices from Zillow. I manually searched for these houses and found the Zestimate for each. After trying to run the code in Pycharm, I repeatedly received an error on the initial scaling of the data:
homes[['prices_scale']] = homes[['prices']]/100000
homes[['sqft_scale']] = homes[['sqft']]/1000
I concluded that the error was due to missing values in the square foot column for houses that did not report square footage anywhere on zillow. This caused these values to spit back more html code. In order to avoid skewing the data, I replaced these 8 homes with other randomly chosen houses in Austin that had values for each metric we are measuring.
Ultimately, I continued with 392 data points in my homes csv. Here is some of the descriptive statistics of the data:
Mean Price: 650557.6198979592, Min: 100,000, Max: 10,995,000, Std: 968.2185799931642, Var: 937447.2186439793
Mean Sqft: 1987.2551020408164, Min: 401, Max: 10,887, Std: 968.2185799931642, Var: 937447.2186439793
Mean no_beds: 3.2448979591836733, Min: 1, Max: 8, Std: 0.9601920576192067, Var: 0.921968787515006
Mean baths: 2.642857142857143, Max: 6, Min: 1, Std: 0.8846517369293828, Var: 0.782608695652174
And two boxplots:
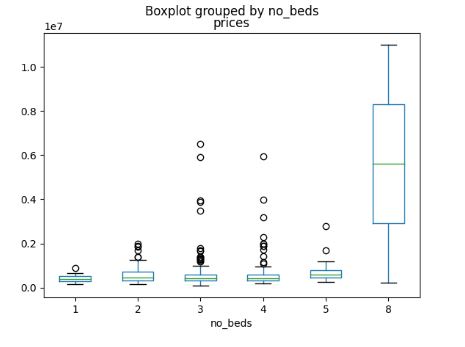
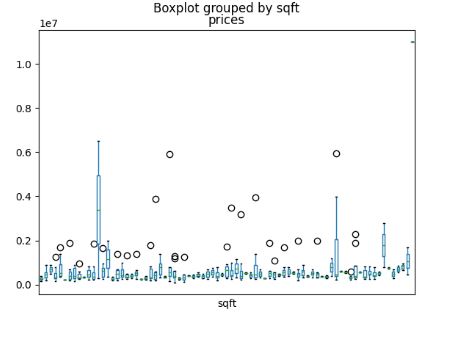
We can see from this data that there exists a small number of outliers in sqft and no_beds on the higher ends of the spectrum. Further, the median price of all of the houses was 425,000, and when we compare this with the mean, we can see that these higher data points probably did skew the central tendency slightly upward. The data points that were concentrated near these higher values were overwhelmingly predicted as bad investments by my model.
Model Architecture
The model architecture itself is similar to the model we used for our previous list of 6 homes in Mathews, VA. We have a sequential neural network that contains a single dense layer with the input shape set for the amount of variables chosen as the key analysis metrics. This was the original code I used for the model:
model = tf.keras.Sequential([keras.layers.Dense(units=1, input_shape=[3])])
model.compile(optimizer='sgd', loss='mean_squared_error')
history = model.fit(x_1, y, epochs=500)
I attempted to create three arrays to use in a stack in order to train my neural network. I received some errors when I first tried to create these arrays because the shapes of my inputs were different between my x, x_1, and y values. After some unsuccessful attempts at reshaping and massaging these variables, I changed the input_shape=1 and was able to produce some graphs:
Output Analysis
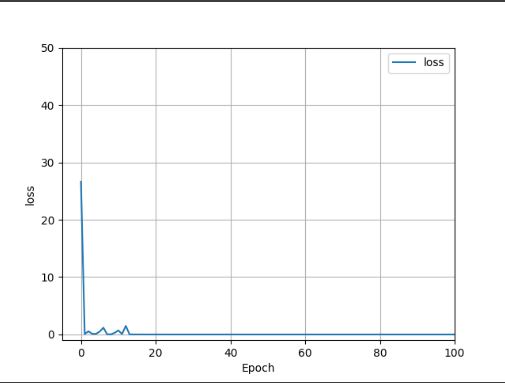
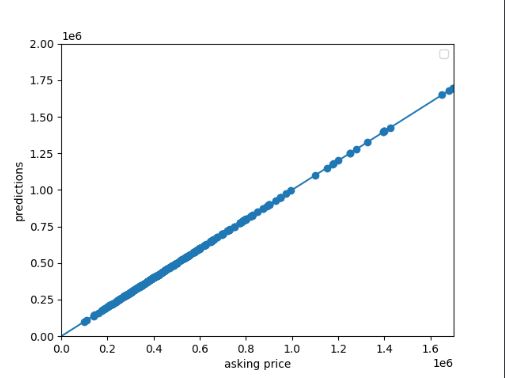
Upon first glance, the plots I generated describe a dataset that is very overfit to the graph trendline. After a discussion and a workshop with our TAs, I decided to push forward with the graphs that I was able to generate due to time constraints. I believe the overfit graph can be explained by the issues that I had with the stack earlier in my model architecture.
The MSE of the raw data was around 5.061940368, which again alludes to a seriously overfit model; this can also be seen in the matplotlib graphs that I included in the Housing Data section.
Here are the best predicted deals based on my data for these houses:

After generating this list I ran some statistics on the differences between the predicted and asking prices. Given how overfit our model is, the predicted values are usually very close to the actual price. However, I still checked whether the model is predisposed to over-predictions or under-predictions. Overall, my model tended towards overpredictions, as more than half of the predicted values were higher than the asking price. However, we must be careful in extrapolating these results.