### DATA 310 - Antonio Marra Response 3 ###
Q: Modify the existing filter and if needed the associated weight in order to apply your new filters to the image 3 times. Plot each result, upload them to your response, and describe how each filter transformed the existing image as it convolved through the original array and reduced the object size. What are you functionally accomplishing as you apply the filter to your original array (see the following snippet for reference)? Why is the application of a convolving filter to an image useful for computer vision?

Pictured above is the first iteration, unedited, of a home built in a modern style.
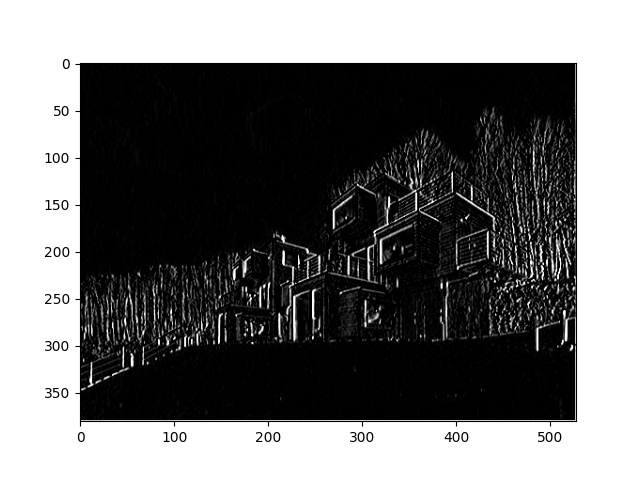
Here is the same picture but with a filter that accentuates the vertical lines on the image.
vertical filter = [ [-1, -2, -1], [0, 0, 0], [1, 2, 1]]

And finally, a filter that accentuates the horizontal lines in the image rather than vertical.
horizontal filter = [ [-1, 0, 1], [-2, 0, 2], [-1, 0, 1]]
Essentially, changing the filter on each image establishes different weights for the filtration of the color values for each pixel. Convolution itself is a helpful tool for allowing a computer to identify the correct filters to apply to an image. The “correct” filter can be chosen and refined through a loss function and optimizer.
Q: Another useful method is pooling. Apply a 2x2 filter to one of your convolved images, and plot the result. In effect what have you accomplished by applying this filter? Does there seem to be a logic (i.e. maximizing, averaging or minimizing values?) associated with the pooling filter provided in the example exercise (convolutions & pooling)? Did the resulting image increase in size or decrease? Why would this method be useful? Stretch goal: again, instead of using misc.ascent(), apply the pooling filter to one of your transformed images.
Using a 2x2 filter on this image works as a compressor for the image itself. This would compress all of the pixel values proportionally and create an image that may be slightly less focused than its 3x3 counterpart, but it uses less memory. These smaller images are easier to run through models and other processing.