DATA 310
Country: Colombia
Data source: Standard DHS Survey Data, 2015
Raw
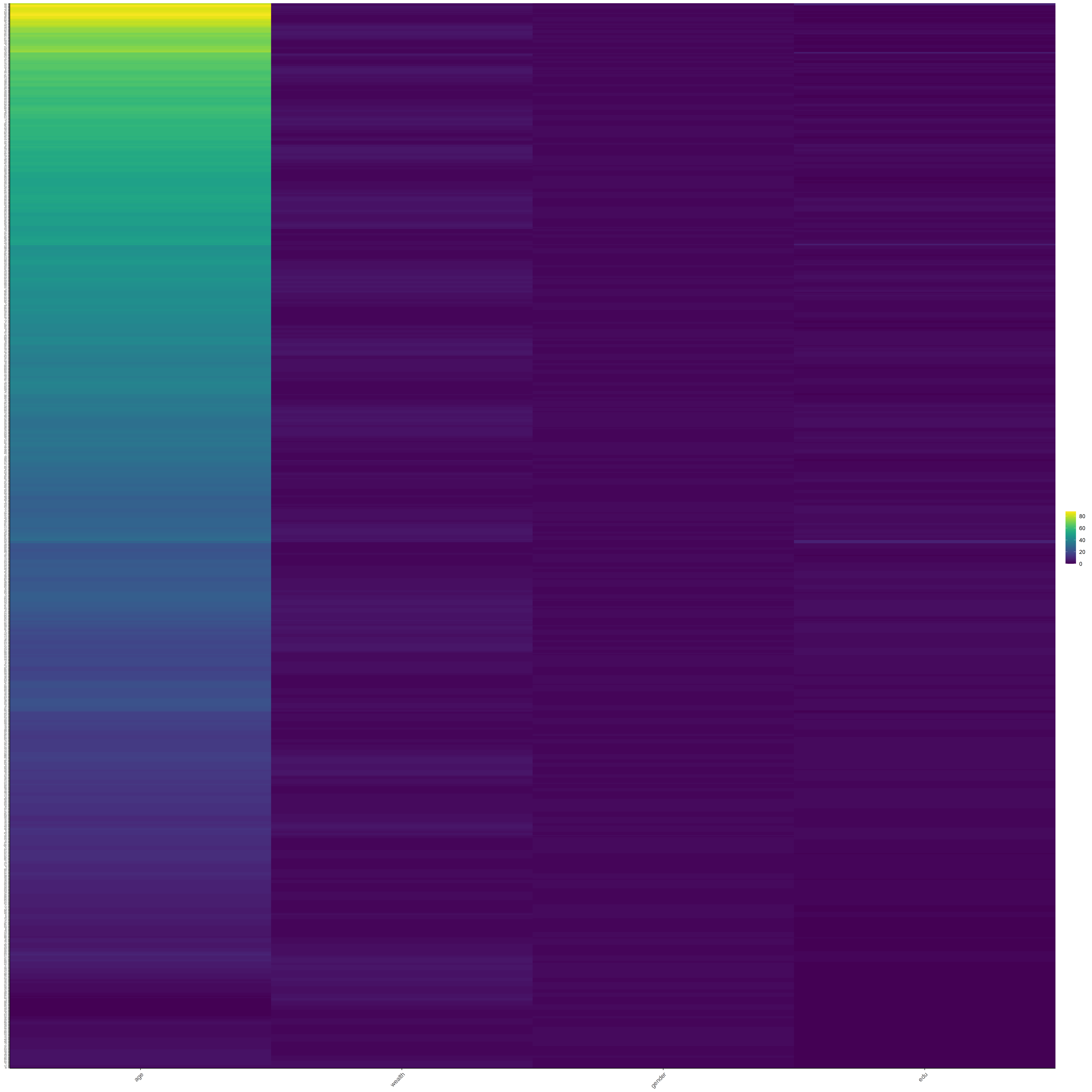
Scaled

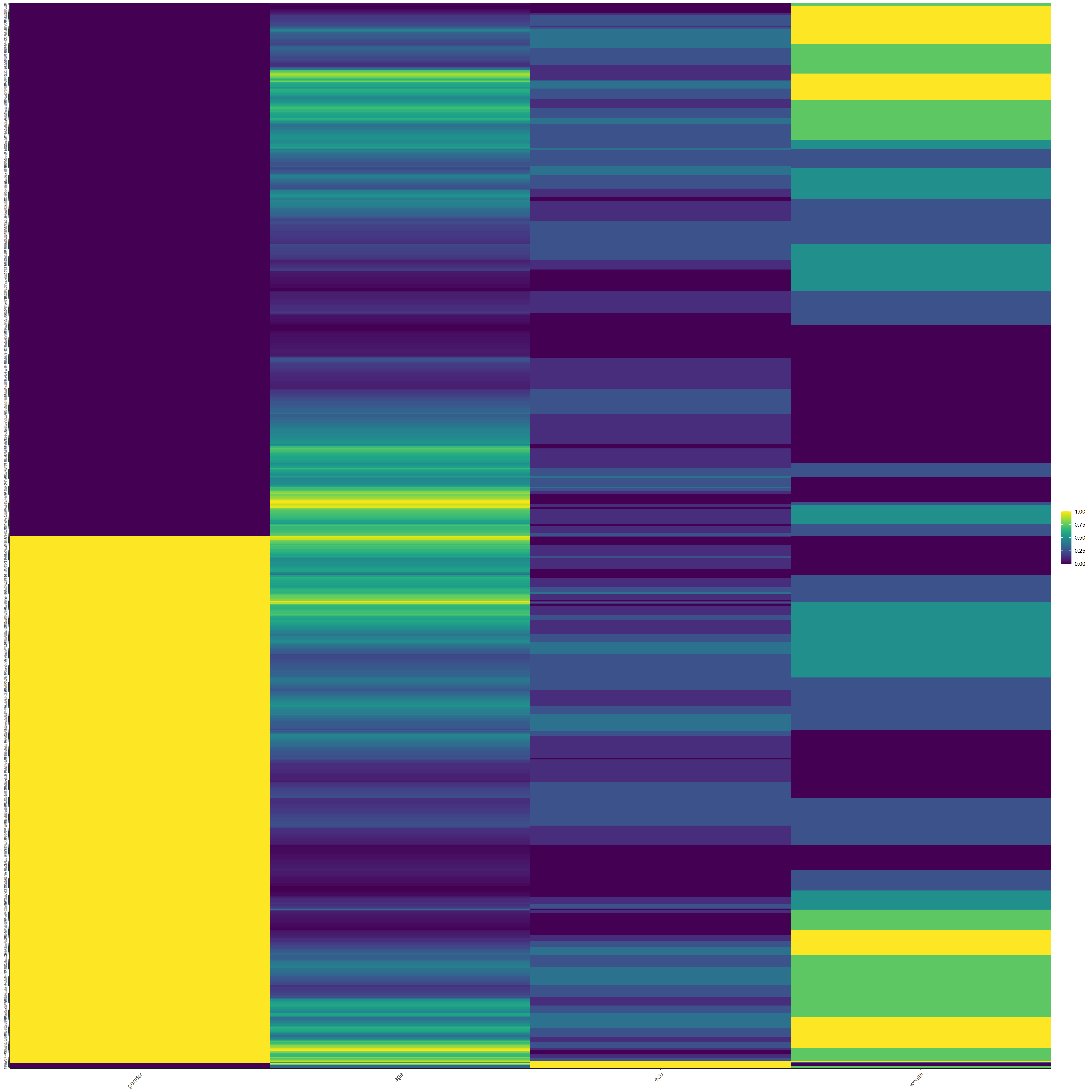
Normalized
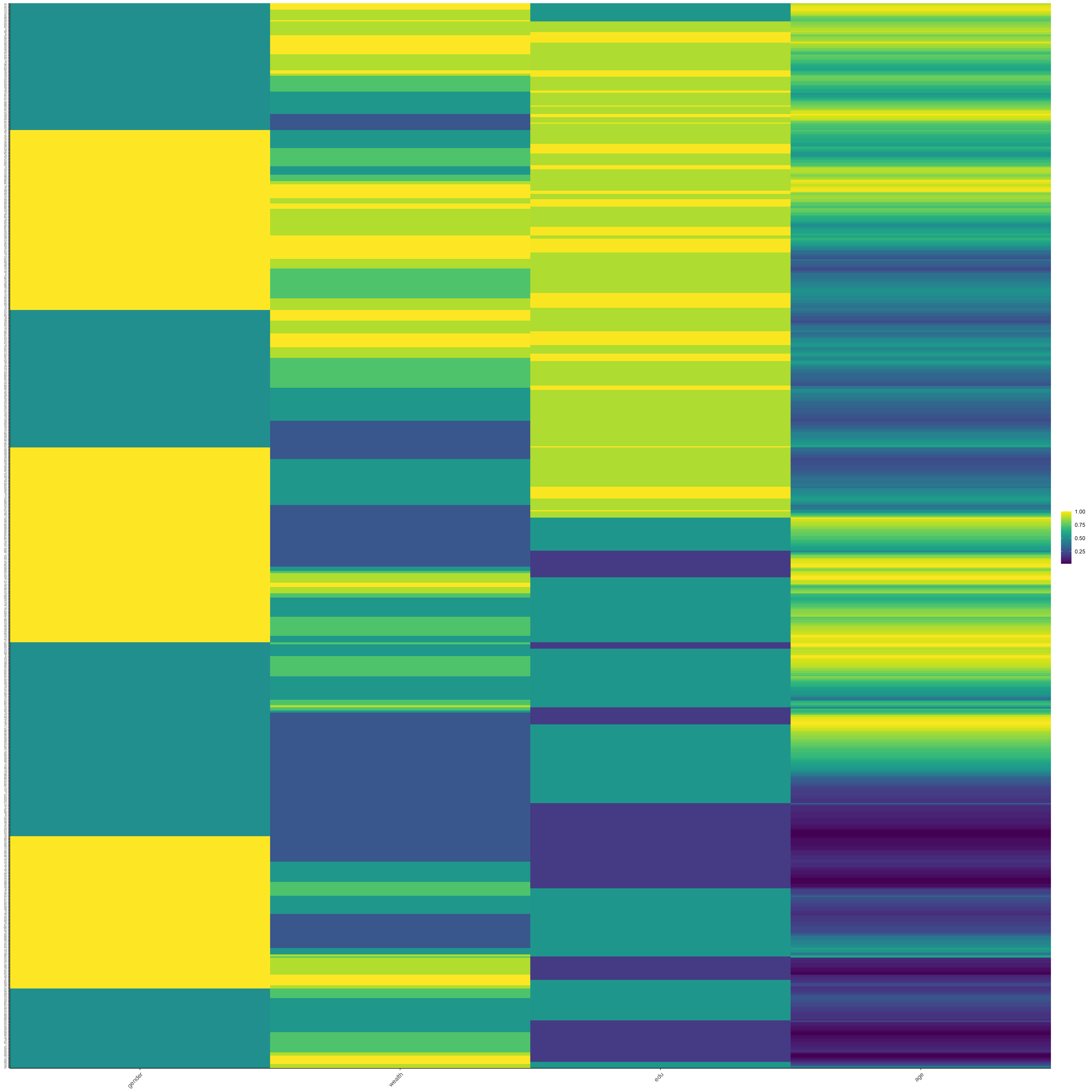
Percentized
Code used to read and pivot the data:
library(haven)
library(tidyverse)
households <- read_dta("C:\\Users\\anton\\PycharmProjects\\DATA310\\project2\\data\\COHR61DT\\COHR61FL.DTA")
hhid <- households$hhid #check length(unique(hhid))
unit <- households$hv004
weights <- households$hv005 / 1000000
location <- as_factor(households$shdepto)
size <- households$hv009
sex <- households[ ,227:247]
age <- households[ ,248:268]
edu <- households[ ,269:289]
wealth <- households$hv270
hhs <- cbind.data.frame(hhid, unit, weights, location, size, sex, age, edu, wealth)
gender <- hhs %>%
pivot_longer(cols = starts_with("hv104"),
names_to = "pid",
values_to = "gender",
values_drop_na = TRUE)
age <- hhs %>%
pivot_longer(cols = starts_with("hv105"),
names_to = "pid",
values_to = "age",
values_drop_na = TRUE)
edu <- hhs %>%
pivot_longer(cols = starts_with("hv106"),
names_to = "pid",
values_to = "edu",
values_drop_na = TRUE)
gender <- select(gender, -starts_with("hv"))
age <- select(age, -starts_with("hv"))
edu <- select(edu, -starts_with("hv"))